首先简单看一下对比学习领域DINO同时期或之前工作的经典方法,主要是这两个,1.simCLR结构比较经典,也比较简单; 2. DINO的模型结构与BYOL相近,
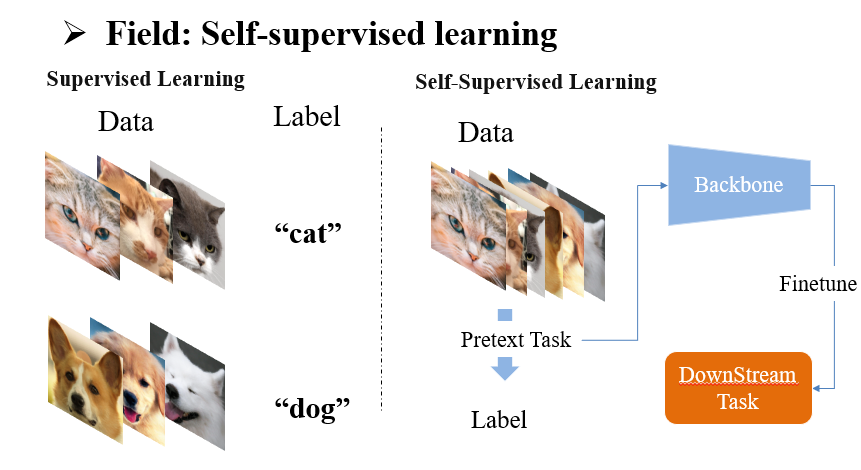
首先对比学习是种自监督学习方法。有监督学习中每条数据的Ground Truth,或者说语义标签,来自于人工标注,比如图示中用于分类的类标签dog/ cat ,但自监督学习没有利用人工标注,而是从无标注的数据中构造 label ,而这个过程可以看作一个 pretext task,委托任务或者说代理任务,比如说 MAE 中将随机遮挡的图像作为输入,原图像作为ground truth,设计损失函数让输出与原图像尽可能相似。我们可以期待在一个设计合理的pretext task中,其训练的backbone网络能被驱使着多多少少学习到,如何表达无标注数据的语义特征。
自监督学习的场景往往是在大量无标注数据上预训练模型,之后再在标注有限的下游任务中微调模型参数

那么很显然,不同自监督方法的一大区别是可以设计不同的代理任务,而对比学习中通常构建一个个体判别Instance discrimination的任务,这个task简单地说就是,既然无标注数据每张图片,都没有label,那就每张图片都各自临时对应一个独特的label好了,也就是如果把这个任务看作分类,那么每张图片单独作为一类,模型训练的目标就是尽可能把各张图片区分开来。其次呢,一张图片x可以通过数据增强得到一些图片(),这些图都可以视为相同label,彼此互为正样本。而数据集中以外的图片,和 的label不同,彼此互为负样本。假设通过模型f提取图像特征,那么损失函数的设计原则就是最大化正样本特征的相似度,最小化负样本特征的相似度。

以上就是个体判别任务的流程,实质上这个任务给学习到的特征施加了两个约束,首先是Alignment,也就是训练中损失函数迫使模型拉近正样本间的距离,因为正样本是同一张图像增强得到的不同图像,宏观上看是将相似的图像聚集了。数据增强中底层的视觉特征容易改变,比如旋转改变了像素纹理方向,而更抽象的语义特征不容易改变,比如一张cat的图像旋转后里面的cat还是只有两只耳朵两只眼睛。
让模型在这种过程中学习到对某些变换(例如平移,旋转,缩放等)不敏感的特征,而这种特征恰好就包含了图像的语义,因为图像无论平移,旋转,缩放,其语义是不变的
Alignment这一约束保障模型能提取出数据增强中不变的语义信息;另一方面,Uniformity这一约束拉开了负样本间的距离,这将驱使无标注数据中每张图像在特征空间中均匀分布,Uniformity是有必要的,如果没有这个约束,那么模型就存在一个捷径解,那就是收敛时所有图像都输出相同或相近的特征,这样学到的特征没有意义,因为区分不开不同图片了,或者说模型只学到了所有数据共有的,更底层的语义。可以说Alignment和Uniformity是很多对比学习工作的方法论
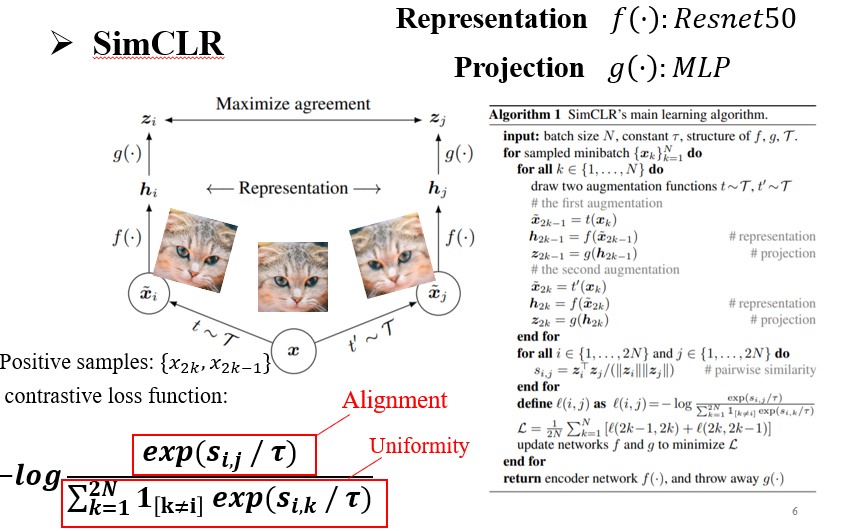
DINO模型结构相对复杂一点,首先来看相关工作SimCLR的结构,首先构造正样本和负样本,假设bactch_size为那么其中每张图像通过数据增强得到个正样本,这一对正样本与其他个增强数据互为负样本。损失函数的话是softmax+交叉熵的形式,所有样本计算余弦相似度,损失函数分式中分子是一对正样本的相似度,分母是其中一个正样本与所有负样本相似度之和,这样模型参数优化中会受到 Alignment与Uniformity两种约束,符合对比学习的套路。在模型结构上呢分为两部分,Representation 部分用Resnet50提取特征,后面Projection是一层MLP。最终舍弃Projection层,只保留Representation网络
如果没有Projection层,那么在对比损失函数中就是直接比较Resnet50提取的图像特征相似度,这会让正样本特征直接趋近,但正样本是同一图像数据增强得到的,这样得到的特征会损失数据增强相关的语义信息。例如一张猫的图片 旋转不同角度的图像特征相近,那就难以通过特征分布分辨猫的头是朝那边的了。加上一层MLP的话,正样本间就可能不需要特别趋近了,只要特征过MLP的结果趋近就行,一定程度上保留下了数据增强相关的语义信息

下面讲BYOL,首先这篇工作follow了simCLR的架构,其次DINO的模型结构大体与BYOL一样,因此原理上只重点讲一下BYOL,它和simCLR最大的不同是没有负样本了,只利用正样本,正样本还是成对的,损失函数就是正样本间的MSE,但是还记得我们之前说过对比学习往往要靠负样本对特征施加Uniformity约束吗
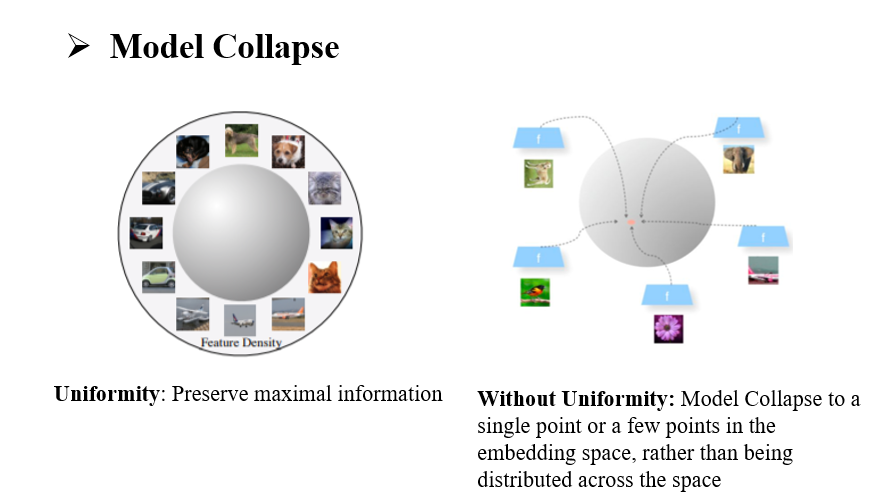
可以肯定的是,没有Uniformity的对比学习是容易模型坍塌的,也就是特征空间中所有样本点集中到一起,因为Uniformity是样本间的斥力,而Alignment是样本间的吸引力
为什么BYOL能避免模型坍塌,这件事可能比较微妙,但很可能是BYOL中的非对称模型结构导致的,我认为主要有以下两点原因

首先BYOL中一对正样本送入的两支网络不是同一个网络(simCLR中是同一个),而其中一支叫做online network(上面一支)target(下面),target作为辅助网络,最终只保留online的repersetation层.online是通过损失函数的梯度更新的,而target network在梯度计算中直接detach掉了,每次迭代target 网络会去直接照搬online网络的权重,但每次只会照搬一点点,也就是动量更新,其中每次更新中自身参数权重为,因此target 网络可以看作是在和online网络同步训练,但更新速度远慢于online。由于随机初始化,target初始时特征分布是分散的,训练过程中online网络的特征分布不断地对target的特征分布进行拟合,而由于动量更新,target的特征分布改变的慢,因此起码在训练初期可以维持住一定的Uniformity
但是动量更新应该是无法完全避免模型坍塌的,如果target 网络通过动量更新,其参数与online网络特别相近时,那就可以看作同一个网络,此时就和simCLR一样了,那肯定会有模型坍塌的问题,因此BYOL的关键可能在于引入了一个非对称的prediction层,这一层和projection一样也是普通的MLP。我们可以从以下角度理解这个改进,模型坍塌是说特征集中到同一点,或者说模型输出常数,因为只有ALIgnment约束的话这就是最优解,这样模型会没法继续更新。而多加入一层MLP的话模型训练时拟合的就是online的prediciton的分布与target的projection,那两支网络在projection层的分布就不一定相同,而projection层之前target网络参数是来源于online的,因此target网络肯定能继续更新(参数存在差异),上下两支网络就很难把最终的Loss降下来。可以把这个prediction理解成一种随机扰动,让上下两支网络难以陷入稳定的输出一致的状态

然后来看DINO,DINO的话也是一个非对称结构,与BYOL不同,DINO去掉了prediciton,而是在target网络,也就是动量更新参数的那个网络上加入了一个Centering操作,实际上就是去均值,target网络会维护一个变量,是target网络所有输出的指数移动平均,Centering强行改变了target输出的分布,让target网络的输出减去均值,target输出的特征分布便很难聚集到一点,online的输出分布又是需要去拟合target的,因此保证了最终模型的Uniformity。但是去均值操作可能让target输出接近均匀分布,这样online学到的输出也可能是均匀分布,那就没有意义了,因此Centering后接softmax放大输出中各维度的差异,online后也接softmax,DINO损失函数是两个softmax得到分布的交叉熵,效果也是拉近正样本间的距离
以上就是DINO的架构原理,下面我们按写作顺序看看原文
从文章标题Emerging Properties in Self-Supervised Vision Transformers看,这篇论文的工作就是把视觉Transformer模型和自监督结合起来。
首先来看motivation,ViT一般比卷积网络参数量更大,训练时间更长,是数据驱动的模型,但有监督的vit学到的特征可能缺少可解释的特性。而在NLP中,BERT等模型通过自监督预训练,一定程度上可以表征更高层的语义信息,比如通过可视化注意力权重可证明模型学习到了句子上下文的关联,因此作者主要参考了视觉领域中的自监督学习的工作,这里主要引用了篇,SwAV, simCLR,MOCO,BYOL,都用的是对比学习,DINO改进了对比学习的网络结构,提出新的避免模型坍塌的方法,而且之前工作中represetation层一般用卷积网络,这里换成了ViT,是一个创新的地方
而Contribution主要是,DINO通过自监督预训练使ViT学到了富含语义信息,而且适用于下游任务的特征。下面这个图中是将ViT的class token相关的注意力权重可视化的结果,可以看到ViT学到了场景布局、物体边界等空间结构上的语义。其次,将预训练的ViT用于Imagenet的分类任务上,特征分类器只用简单的k邻近就能达到的acc。最后作者强调了网络结构,具体改进前面说了,作者把他的对比学习方法强调为无标注的知识蒸馏,这也是DINO简称来源
相关工作部分,作者首先讲了使用负样本的对比学习的缺点,那就是一个正样本要和足够的负样本去比较,不然Uniformity的约束肯定很弱,那就学不好,通常每个batch中不同图片互为负样本,那这就要batch_size足够匹配数据集大小,这种方法在大型数据集就会受限于batch_size

作者将DINO的对比学习视为一种知识蒸馏,这一种不同视点的解释也更能支撑文章的方法吧。在这里,他将使用梯度更新的网络叫做student,动量更新的网络称为teacher,一般知识蒸馏是student拟合teacher,teacher是固定的。但这里teacher也是通过动量更新与student缓慢同步的,简单来说,DINO就是让模型不断从以前的自己学习,总结student学到的知识然后超越teacher,通过自我内卷让自己从无到有训练出一个好的backbone(really?)

下一部分Approach,之前讲了原理,那就只看一下几个细节,作者提出方法的切入点是知识蒸馏,而知识蒸馏中通常用交叉熵损失函数拉近student-teacher的输出分布,所以DINO沿用了了交叉熵损失。第二,正样本在数据增强前都是通过随机裁剪获得,student网络使用大尺寸裁剪,teacher使用小尺寸,根据对比学习的方法论,我们可以鼓励模型学习到局部-全局视图下不变的特征。第三,不使用BN,因为BYOL这篇工作避免模型坍塌的机制被质疑是BN作用。(但是BN有去均值,centering不就是近似去均值了么?)
然后作者解释了防止模型坍塌的策略,这个之前讲过了,作者这里强调了一下centering中teacher的输出均值是动量更新的,那受batch_size影响就比较小,batch_size较小的话计算的均值偏差大,动量更新的话可以减小偏差对的影响
Approach的下半部分主要介绍了训练的具体实现,数据集是Imagenet的去标注数据,训练用的模型有resnet50, vit-b, vit-s,完成与训练后要在下游任务上对学到的特征进行评估,因为对于无监督或自监督,在下游任务中表现好预训练的特征才是好的特征,这里下游任务是imagenet验证集上的图像分类,后面实验中用了两种方法做这个下游任务,在预训练模型后接一个线性分类器,或k邻近分类,这两个分类头的区别在于线性分类器会finetune预训练模型,而knn无参数,不调整预训练参数。

实验部分,作者为了给自己的Contribution提供支撑,也把结果分为两部分,首先在imagenet上验证ViT学到的特征适用于下游任务;其次分析了ViT学到的特征的语义。首先在imagenet上,作者与其他自监督工作的横向对比,使用相同的backbone网络resnet50时,DINO达到SOTA。在使用Vit-s时outperforms BYOL, MoCov2 and SwAV by +3.5% with linear classification and by +7.9% with k-NN evaluation.
另外作者的一点发现就是DINO backbone使用vit-s时KNN相比于linear准确率降得很少,那这说明vit学到的特征分布已经比较接近ImageNet验证集的数据分布了啊,所以linear这种有参数的分类器虽然可以缩小两者的gap,但提升效果更有限。所以作者认为vit学到的特征可能更适合直接比较特征的下游任务,因此还做了相关的后续实验。
其次是DINO改用不同的backbone网络的纵向对比,相比于在vit中增加Transformer层数。这是很自然的结果,减小vit分割图块的大小的话vit将输入图片转换成的token序列就变长了,输入信息损失更少,更容易学到好的表征。这与vit原文中有监督任务一致,减小图块的大小提升模型性能。(ViT-B/(8 × 8 patches) with DINO achieves 80.1% top-1 in linear and 77.4% with a k-NN classifier with 10× less parameters and 1.4× faster run time than previous SOTA(SCLRv2))
在实验第二部分,作者试图解释DINO自监督的viT学到的特征的特性,一共是三个特性:一是特征直接用于检索,二是学习到了图像中物体位置的信息,三是到下游任务良好的可迁移性
首先作者观察到vit+kNN在IMAGENET上的表现,DINO中vit学到的特征可能适合直接用于检索,在图像检索任务上使用kNN对backbone输出的特征进行检索,可以看到,使用DINO预训练时,vit-S在两个数据集上表现比有监督训练的好,另外作者强调自监督的优点在于可以用大量无标注数据进行训练,在换了个大型数据集后,vit-s的平均准确度接近了有监督的resnet101
DINO+viT的第二个特征是能学到图像的结构信息,vit中把输入图像的所有patch转成token序列后,会再加入一个class token, 最终输出为通过transformer encoder的class token,所以class token与其他patch的注意力分数就体现了vit最终输出的特征更注意原图中哪些位置,把注意力分数还原到每个patch对应的位置,然后可视化得到一个self-attention map,可以看到这个map明显体现了原图的空间结构,所以作者认为viT的特征适合做图像分割任务,甚至这种可视化的self-attention map也可以用来直接做分割任务。【vit原文中用的是 attention rollout算法可视化attention map】
于是作者首先利用DINO预训练的vit,在DAVIS-2017数据集上做视频实例分割任务,作者说只直接利用连续帧的特征做分割,不对预训练模型finetune,结果Vit-s/8比有监督方法还要好,足以说明DINO中的vit确实学到了一些空间结构信息

然后作者又对vit的self-attention map做了一些其他实验,首先class token与其他patch的注意力分数之和为,作者只保留部分patch,使其注意力分数之和不超过0.6,保留的patch直接作为图像分割的mask。这样做的话,在PASCAL VOC12数据集上,DINO自监督预训练的的vit-s甚至比直接有监督图像分割的性能好

其次我们刚才可视化的是class token在所有注意力头上与其他patch的注意力分数,接下来作者把 每个自注意力头对应的self-attention map用不同颜色绘制后叠加,可以看到不同attention head注意的是图像不同的部分,佐证了dino可以引导模型学习一些高层的语义。
DINO+viT的第三个特征是能学到迁移性好的特征,因为自监督的对比学习中,模型训练中不以人为定义的label为导向,学到的可能是更通用的语义信息。为在一开始的实验中,DINO的viT是在去除标注的imagenet训练集预训练的,而下游任务是imagenet验证集上的图像分类,同源数据说明不了预训练模型的可迁移性,所以作者有针对这一点做了新的实验,同样是imagenet上预训练vit,但在不同数据集上微调模型做下游任务,结论是DINO比起有监督预训练在不同下游任务的泛化性更强,指标上基本高个点。
最后是两个消融实验,首先作者想证明DINO网络结构中各个部分的有效性,于是对比了几种DINO结构的变种,加上参考工作中的结构或是删除原有部分。可以看出对于提升预训练效果比较关键的部分是DINO默认使用的交叉熵loss,以及对正样本采用不同尺寸的裁剪。不使用动量更新的策略时,发生了模型坍塌,所以无负样本对比学习的一个关键可能是构造非对称的网络结构,另外就是验证了减小vit中图块的大小能提升模型自监督训练的效果